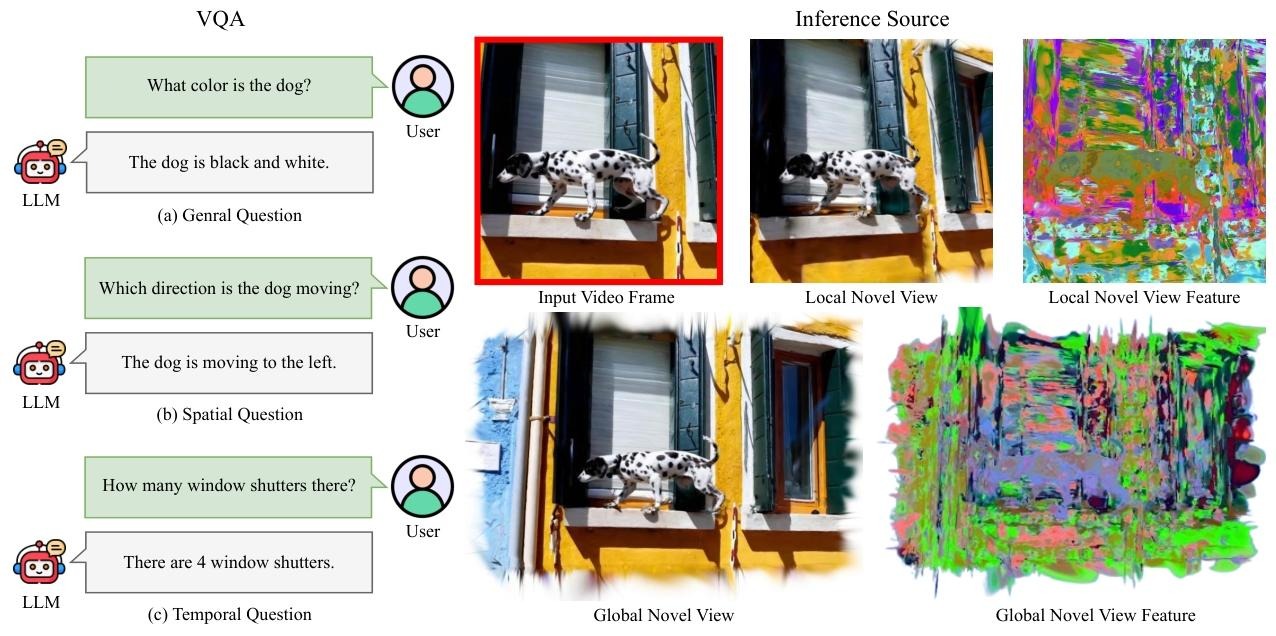
✦ Overview ✦
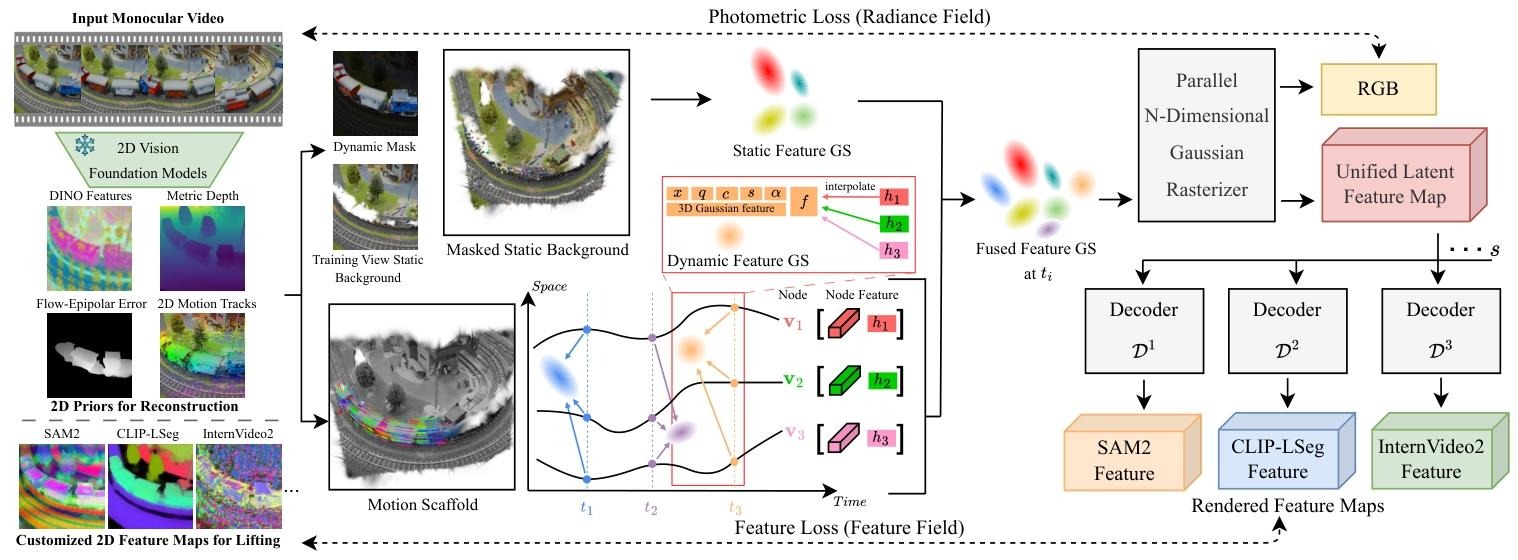
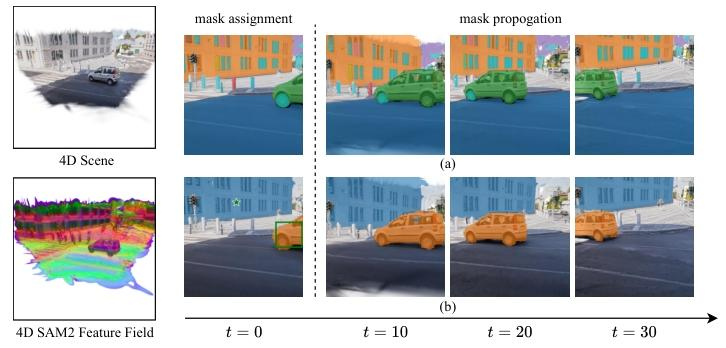
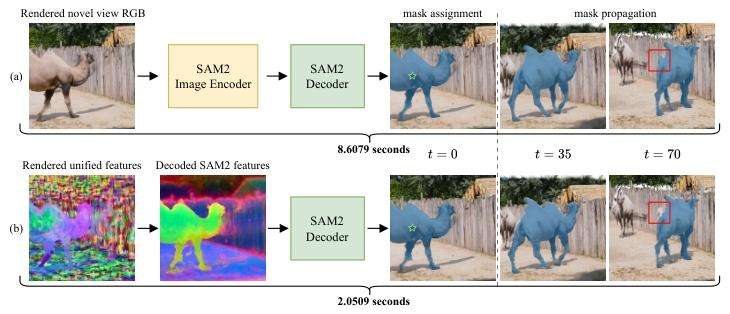
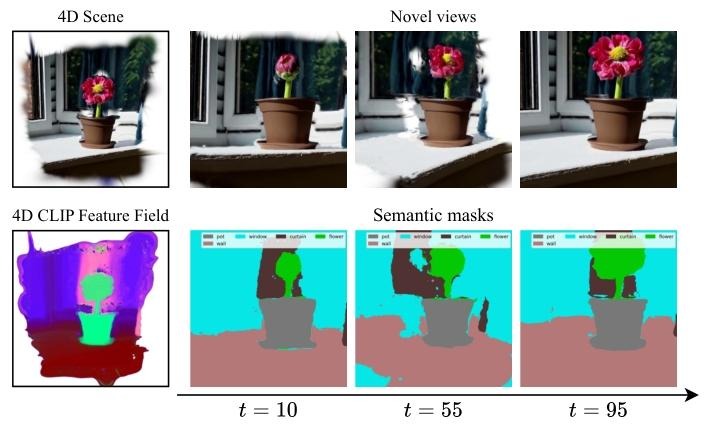
Given an input monocular video, we infer 2D priors to segment static background (represented by static 3D Gaussians augmented with latent features) and dynamic foreground (represented by dynamic 3D Gaussians guided by Motion Scaffolds, a set of nodes {vi} encoding 3D motion trajectories and latent features h1). Dynamic Gaussian features and motions are computed via interpolation from their K-nearest scaffold nodes. At each timestep, dynamic Gaussians are warped and fused with static Gaussians. A parallel rasterization generates RGB images and a unified latent feature map, decoded into task-specific features—illustrated here by SAM2, CLIP-LSeg, and InternVideo2 for representative 2D (novel view segmentation), 3D (scene editing), and 4D (spatiotemporal VQA) tasks. Our framework generalizes to any 2D vision foundation model and is trained end-to-end using input RGB frames and customized features from pretrained 2D models. At inference, rendered feature maps from arbitrary views and timesteps are directly fed into task-specific decoders, seamlessly supporting user prompts and LLM interactions to form a unified 4D agentic AI system.